
Personal Artificial Intelligence
10 Jun 2025There’s a lot of buzz around OpenAI building a hardware device that is always on and records everything you hear, see, and speak. This is in line with what I have been proposing here.
Having trained on all the data on the internet, AI models are moving closer and closer to Artificial General Intelligence (AGI). Once AGI continues to improve, the cost of knowledge drops to zero (or something negligible). Everyone has access to the same knowledge, which stops being a differentiator.
Experiences now take over. Person A would be different from Person B, not because A knows more knowledge than B, but because A has had different experiences than B. A novelist may draft stories steeped in their childhood memories, while a screenwriter may write scripts that mirrors their years in L.A.’s film scene.. The content I would consume more is influenced by the fact that I have an engineering and an MBA degree, lived in India, UK, and the US, and so on. That is, it will be influenced by everything I have experienced.
What exactly is experience? Its defined as practical contact with and observation of facts or events. What does the new recording device do? Record everything you came into practical contact with and your observations of events. Essentially, OpenAI is trying to record one’s experiences, so that the answers can be more personalized.
AGI + Experiences = Personal Artificial Intelligence (PAI?)
Today’s models are good at absorbing and analyzing language, hence the minimum viable product to prove the concept should simply be a recording device, which is precisely what Limitless is doing.
Using content from the recording, we can train a system on the user’s experiences. A potential implementation of the system is as follows, which is influenced by the Neural Turing Machines paper that I read as part of my CS375 class at Stanford.
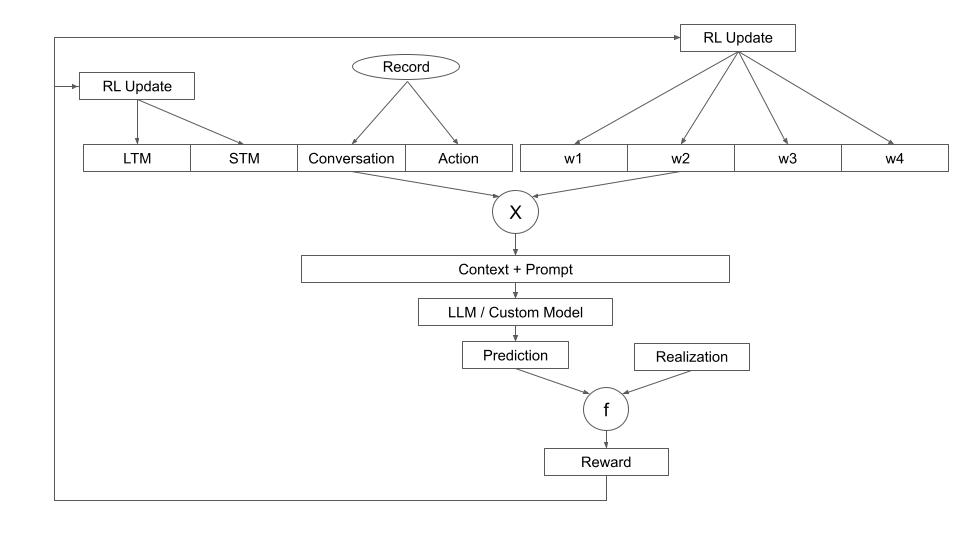
The user’s speech and environment is being transcribed constantly by the system, until it hears a potential action from the user. A potential action could be something like: “I wonder what I was doing this time last week”. The system then generates the appropriate context and prompt to an LLM or a custom model by accessing the users Long-Term Memory (LTM), Short-Term Memory (STM), the current conversation, and the requested action. Weights/access parameters are tuned to generate the context and prompt combination.
Once a prediction is made, it can be shown to the user if the system is reasonably confident. If the confidence is low, the system can avoid showing it to the user. Either way, a realization is obtained as the user continues to speak, which can be compared with the prediction to generate a suitable reward. This reward can then be used to update the LTM, STM, and the weights/access parameters, along the lines of the Neural Turing Machines paper.
Across different users, the contents of the LTM and STM and the corresponding RL update may vary. However, my guess is that the weights/access parameters may be similar across multiple users. Either way, it is the LTM, STM, and the weights/access parameters that determine the quality of the system and delight the user.
The device need not have a screen, but it should integrate well with existing phones and laptops. We don’t need to reinvent the wheel of smartphones and tablets. There is a lot of potential for innovation in the software on top of the recording device.
While there will be privacy concerns on whether such a device is ethically appropriate, the human brain already does continuous ambient recording and reproduction. This device merely helps the human brain do its job better. Once users see the value add in such a device, they may be willing to overlook these concerns.